
Automatisierung von Dokumentationsaufgaben in der Pflege – Verbesserung eines KI-Modells zur Bestimmung inhaltlicher Übereinstimmung von Texten
Im Rahmen der Erstellung eines KI-Systems zur Dokumentation von Arbeitstätigkeiten im Pflegesektor wurde ein allgemeines STS (Semantic Textual Similarity), zu deutsch Semantische Textnähe, Modell entwickelt. Basierend auf einem existierenden Ansatz für Textvergleiche in den Sprachen Deutsch und Englisch, werden Verbesserungsmöglichkeiten identifiziert und letztendlich in einem Modell-Training realisiert. Es ergibt sich eine Performance-Steigerung von 1 bis 5 Prozentpunkten. Insbesondere die Einbindung mehrerer Datensets erlaubt eine robustere Näheberechnung zwischen Sätzen bzw. Texten. Eine generelle Einschränkung mit STS muss die Forschung alsbald angehen … Beitrag von Philipp Müller
Einbindung von KI in der Pflege
In der Pflege nimmt die Dokumentation von durchgeführten Arbeitsschritten einen nicht zu unterschätzenden Anteil der Arbeitszeit ein. So wünschen sich über 85% der Pflegekräfte in einer „Pflege-Thermometer“ Umfrage aus 2018 die Nutzung von Technologie für Dokumentationstätigkeiten, womit der Wunsch nach Entbürokratisierung und ein erleichterter Umgang mit derartigen Verpflichtungen einhergeht. Die Dokumentation von zuvor vereinbarten Zielen und damit damit verbundenen schriftlichen Quälereien betreffen auch viele andere Bereiche und sind Teil einer stetig komplexer werdenden Arbeitswelt. Letztendlich handelt es sich um die Abarbeitung von „Checklisten“, für die kurze Titel oder Beschreibungen je Arbeitsmaßnahme vorliegen.
Mittels eines sprachgesteuerten Systems, so die Idee der Sense.AI.tion GmbH in Zusammenarbeit mit der TH Wildau, werden ausgeführte Arbeitsschritte einfach ausgesprochen und aufgezeichnet. Dies kann sowohl im Moment der Durchführung als auch etwas später geschehen. In der Pflege können so Gespräche zwischen Pflegekraft und Pflegebedürftigen für diesen Zweck automatisch ausgewertet werden. Häufig werden Pflegemaßnahmen gegenüber der zu pflegenden Person sowieso im Gespräch nebenbei ausgesprochen. Dieser Ansatz lässt sich gleichermaßen auf andere Anwendungsfälle, beispielsweise eine Autowerkstatt, anwenden: Die TÜV-Prüfung oder Reparaturmaßnahme wird ins Sprachsystem eingesprochen, dass einen Abgleich mit der vordefinierten Checkliste vornimmt und diese automatisch ausfüllt.
Unterstützung durch KI-Werkzeuge

Auf technischer Ebene lässt sich dabei der Ansatz Semantic Textual Similiarity (STS) bzw. Semantische Textnähe nutzen, welcher angibt, wie ähnlich sich zwei Sätze bzw. Texte inhaltlich sind. Mit Aufkommen der aktuellen KI-Welle entwickelten sich in den letzten Jahren vielversprechende Ansätze, um dieses Problematik unter Nutzung von Machine Learning, respektive Deep Learning, effizient anzugehen. Die Einführung von „Transformer“, zu nennen sind hierbei vor allem BERT, XLM, und T5, ermöglichen es, Zusammenhänge von Worten (Ähnlichkeit, Analogie, Thematik) durch neuronale Sprachmodelle im Kontext darzustellen und hinsichtlich der relativen Relevanz zu bemessen. Ein solches Modell kann anschließend anhand von Trainingsdaten hinsichtlich eines Lernziels optimiert werden.
Bei einem STS-Transformer-Modell, werden Sätze in mathematische Vektoren umgewandelt und können u.a. mit dem Maß der Kosinus-Ähnlichkeit (engl. „cosine similarity“) auf semantische/inhaltliche Übereinstimmung verglichen werden. Im Falle der Checkliste werden dazu Titel/Beschreibung der einzelnen Aufgabe mit den Sätzen verglichen, die durch einen Nutzer in das System schriftlich oder mündlich eingegeben werden.
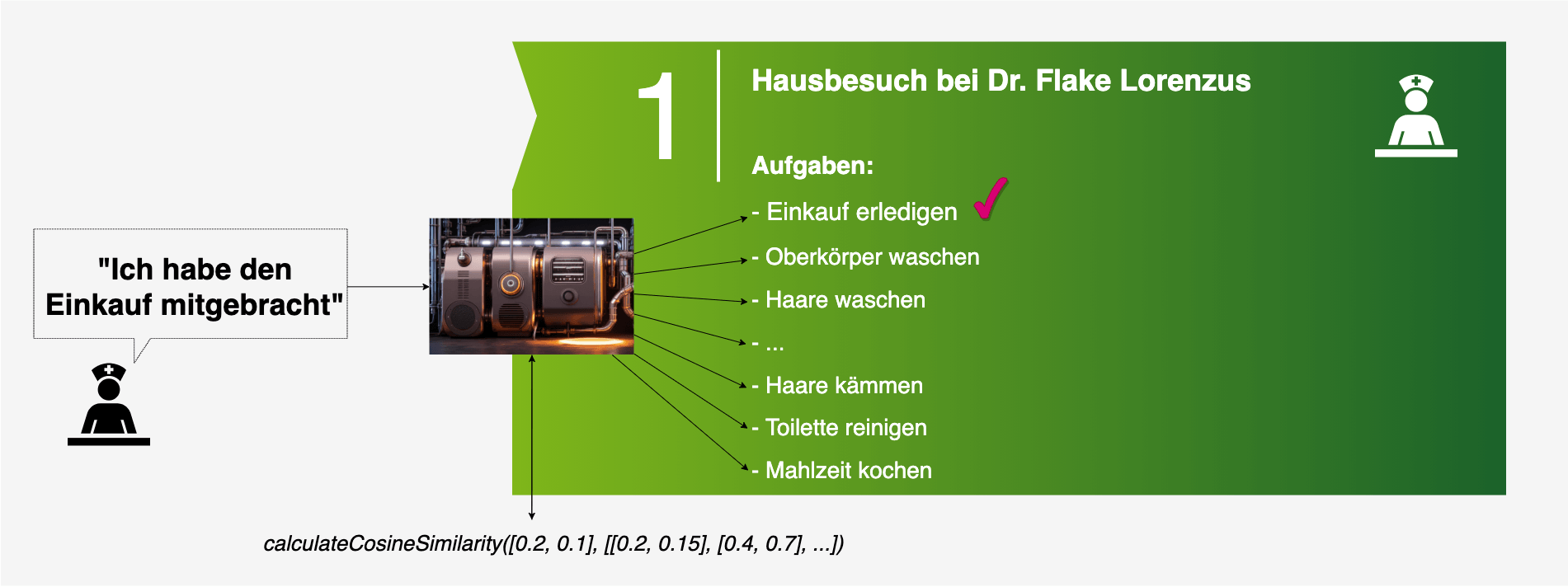
Neben einigen multilingualen Modellen existieren auch wenige deutschsprachige Modelle für die Berechnung der semantischen Nähe von Texten. Mit hunderttausenden Downloads ist hierbei vor allem ein Modell von Philipp May (https://huggingface.co/T-Systems-onsite/cross-en-de-roberta-sentence-transformer) – von nun an „TSystems-Modell“ genannt – hervorzuheben. Dieses basiert auf einem speziellen STS-Datenset, welches mit Hilfe einer maschinellen Übersetzung für die deutsche Sprache nutzbar gemacht wurde. Die Popularität dieses Modells erklärt sich außerdem durch den cross-lingualen Ansatz zwischen Deutsch und Englisch, bei dem die semantische Nähe nicht nur zwischen zwei deutschen Sätzen, sondern auch zwischen englischen und deutsch-englischen-Kombinationen möglich ist.
Die Kombination aus cross-lingualer Verwendbarkeit von Deutsch und Englisch sowie der stetig guten Performance im internen Prototyping bei der Sense.AI.tion GmBH und TH Wildau führte zur Idee, eine Bestandsaufnahme des Ansatzes von Philipp May zu machen und an die aktuellen Gegebenheiten anzupassen. Grob lassen sich zwei Verbesserungspotentiale identifizieren:
- Es existieren neuere Basis-Modelle aus 2022, die für das Training genutzt werden können
- Die Menge an Trainingsbeispielen lässt sich durch weitere maschinelle Übersetzungen anderer Datensets vergrößern. Die Kombination beider Maßnahmen, so die Idee, führt zu einer robusteren und qualitativ besseren Performance.
📚 Details zum Vorgehen für Wissensdurstige 📚
Zu 1:
- Für englischsprachige Anwendungsfälle existieren mit gewaltigem Abstand die meisten Datensets. So basiert das TSystems-Modell in der Basis auf einem englischsprachigen Paraphrasierungs-Modell welches aus 7 verschiedenen Datensets besteht und insgesamt ca. 24,6 Millionen Sätze enthält. Diese zu übersetzen ist zumeist nicht wirtschaftlich.
- Da für die deutsche Sprache (und auch viele andere) nur wenige Datensets zur Verfügung stehen, wird verstärkt die Knowledge Distillation (Teacher-Student-Ansatz) verwendet. Dabei wird ein monolinguales Modell (meistens Englisch-basiert) in ein multilinguales Modell (prinzipiell jede Sprache möglich, in unserem Fall Englisch-Deutsch) umgewandelt. Das TSystems-Modell greift dafür auf exakt diesen Ansatz zu, wobei das Teacher-Modell für über 50 Sprachen optimiert wurde.
- Mittlerweile existiert eine zweite, größere Version des monolingualen Modells mit 12 verschiedenen Datensets und ca. 83,3 Millionen Beispielen. Dieses wurde im Zuge dieses Projektes von uns per Knowledge-Distillation für Deutsch nutzbar gemacht und dient als Ausgangsbasis für das STS-Training. Details können unter https://huggingface.co/PM-AI/paraphrase-distilroberta-base-v2_de-en nachgelesen werden.
Zu 2:
- Das Datenset STSb galt zum Zeitpunkt des TSystems-Modells als einzige Möglichkeit, ein STS-Modell zu trainieren. Es wird auch bei unserem Modell eingebunden.
- SICK, ein weiteres Datenset, wurde in Teilen bereits in STSb verwendet, jedoch führt unsere eigenständige Übersetzung, mittels DeepL, zu leicht abgewandelten Formulierungen. Durch diesen Ansatz lassen sich mehr Beispiele ins Training aufnehmen.
- Das 2022 veröffentlichte Datenset Priya22 semantic textual relatedness wurde gleichermaßen per DeepL ins Deutsche übersetzt und den Trainingsdaten hinzugefügt. Da es über keinen Train-Test-Split verfügt, wurde dieser im Verhältnis 80:20 eigenständig angelegt.
- Die Bewertungsskala aller Datensets wurde an STSb mit einem Wertebereich von 0 bis 5 angepasst.
- Alle Trainings- und Testdaten wurden auf Duplikate innerhalb und miteinander geprüft und bei Fund entfernt. Die final verwendeten Datensets können hier betrachtet werden: https://gitlab.com/sense.ai.tion-public/datasets_sts_paraphrase_xlm-roberta-base_de-en.
Training des Modells und Bewertung der Ergebnisse
Im Anschluss an das Training, gilt es, das neu entstandene Modell mit anderen STS-Modellen zu vergleichen. Dazu wird die Performance sowohl cross-lingual als auch nur für Deutsch und Englisch gemessen. Erweiternd werden die verwendeten Test-Samples je Datenset einzeln (STSb, SICK, Priya22), als auch in einem großen kombinierten Test-Datenset (all) ausgewertet. Diese Unterteilung je Datenset ermöglicht eine faire Gesamteinschätzung, da externe Modelle nicht auf der selben Datenbasis wie das hier vorgestellte Modell aufbauen. Erweiternd werden nur Modelle aufgelistet, welche cross- bzw. multilinguale Fähigkeiten besitzen. Intern findet die Evaluierung auch mit monolingualen bzw. andersartigen Modellen statt. Die vollständige Tabelle kann unter folgendem Link in der „Model Card“ betrachtet werden: https://huggingface.co/PM-AI/sts_paraphrase_xlm-roberta-base_de-en.
Vergleich der multilingualen STS-Modelle nach Spearman Koeffizienten
| Model | STSb | SICK | Priya22 | all |
|---|---|---|---|---|
PM-AI/sts_paraphrase_xlm-roberta-base_de-en (unsers) | 0.8672 🏆 | 0.8639 🏆 | 0.8354 🏆 | 0.8711 🏆 |
| T-Systems-onsite/cross-en-de-roberta-sentence-transformer | 0.8525 | 0.7642 | 0.7998 | 0.8216 |
| PM-AI/paraphrase-distilroberta-base-v2_de-en (unsers, ohne fine-tuning) | 0.8225 | 0.7579 | 0.8255 | 0.8109 |
| sentence-transformers/paraphrase-multilingual-mpnet-base-v2 | 0.8310 | 0.7529 | 0.8184 | 0.8102 |
| sentence-transformers/stsb-xlm-r-multilingual | 0.8194 | 0.7703 | 0.7566 | 0.7998 |
| sentence-transformers/paraphrase-xlm-r-multilingual-v1 | 0.7985 | 0.7217 | 0.7975 | 0.7838 |
| paraphrase-multilingual-MiniLM-L12-v2 | 0.7823 | 0.7090 | 0.7830 | 0.7834 |
| sentence-transformers/distiluse-base-multilingual-cased-v1 | 0.7449 | 0.6941 | 0.7607 | 0.7534 |
| sentence-transformers/distiluse-base-multilingual-cased-v2 | 0.7517 | 0.6950 | 0.7619 | 0.7496 |
| sentence-transformers/distilbert-multilingual-nli-stsb-quora-ranking | 0.7211 | 0.6650 | 0.7382 | 0.7200 |
Tabelle 1: Ergebnis der Evaluierung. Auf einer Skala von 0.0 bis 1.0 werden die Ansätze nach der Metrik „Recall“ bewertet. Hierbei ist 1.0 der beste Wert.
Bei Betrachtung der Spalte „all“, welche das Performance-Ergebnis über alle genutzten Datensets aufzeigt, wird ein Performancesprung von 5%-Punkten erkennbar. Dies ist wenig überraschend, denn das hier vorgestellte Modell wurde als einziges unter Einbeziehung aller Datensets trainiert und jedes trainierte Modell tendiert zu besseren Ergebnissen, innerhalb der eigenen Trainingsdomäne. Außerdem werden Trainings zumeist nicht cross-lingual durchgeführt, d.h. Satzpaare gehören zur selben Sprache, werden aber nicht gekreuzt betrachtet, beispielsweise zwischen Deutsch und Englisch. Diese Herangehensweise wurde, in Anlehnung an TSystems, dennoch bewusst gewählt.
Folglich besteht die beste Vergleichbarkeit zwischen TSystems und unserem Modell, da zumindest STSb als auch der cross-linguale-Ansatz gleichermaßen Grundlage sind. Wird nun ausschließlich die Spalte „stsb“ betrachtet, so fällt der Performance Unterschied mit ca. 1.5 Prozentpunkten deutlich kleiner aus. Dennoch kann sich unser Modell leicht steigern, da die Einbindung weiterer Datensets insgesamt einen positiven Einfluss zur Folge hat. Die bereits im vorherigen Paragraphen angesprochene nicht integrierte cross-linguale Nutzung wird bei Betrachtung des Modells sentence-transformers/stsb-xlm-r-multilingual gut sichtbar: Obwohl das Modell multilingual ist und speziell mit STSb trainiert wurde, performt es im cross-lingualen-Test deutlich schlechter als TSystems und unser Modell. Wird dagegen nur die Evaluierung mit englischen Sätzen in Betracht gezogen (siehe https://huggingface.co/PM-AI/sts_paraphrase_xlm-roberta-base_de-en), so schmilzt der Performance Vorsprung.
📚 Details zum Vorgehen für Wissensdurstige 📚
- Es ist wichtig zu verstehen, dass unser Modell Trainingsdaten von STSb, SICK und Priya22 gesehen hat, weshalb es auch ganz logisch bessere Ergebnisse liefert. Das Modell ist schlichtweg sensitiver für diese Art von Beispielen trainiert worden.
- Die Datensets sind bezüglich ihrer Anzahl von Beispielen nicht in der Verhältnismäßigkeit angeglichen. So ist Priya22 beispielsweise deutlich unterrepräsentiert.
- Die verglichenen Modelle sind von unterschiedlicher Größe, was sich auf Resourcenverbrauch (CPU, RAM) und die Inferenz-Geschwindigkeit (Benchmark) auswirkt. Sogenannte „large“ Modells performen zumeist besser, kosten aber auch mehr (Ressourcen, realer Geldwert) als z.B „base“ Modelle.
- Multilinguale Modelle werden i.d.R. durch Knowledge Distillation, von einem monolingualen Zustand ausgehend, nachträglich multilingual gemacht. Sie performen daher in der Originalsprache meist etwas besser. In der Tabelle lässt sich dies bei den „paraphrase“-Modellen anhand der Ergebnisse für Englisch nachvollziehen – diese sind um mehrere Prozentpunkte besser als für Deutsch.
Ausblick auf weitere Forschung und Entwicklung
Ein häufiges Phänomen ist die inkorrekte Zuordnung bei Sätzen, die keine besondere Komplexität haben und für Menschen mit einem Blick korrekt einzuordnen sind. Aktuell schafft es daher noch kein einziges Modell eine vollständige, korrekte Bewertung vorzunehmen. Der Hauptgrund für dieses Phänomen liegt im Aufbau von STS Datensätzen. Die Nutzung wird in der aktuellen Forschung verstärkt kritisiert, da sie als nicht (mehr) ausreichend für das Training von semantische Nähe zwischen Sätzen eingeschätzt wird. Die Trainingssätze sind relativ simpel und decken viele Themenbereiche nur unzureichend ab. Dies wirkt sich vor allem auf Fachrichtungen (z.B. Pflege, Biologie, Medizin, usw.) negativ aus. Die in der Tabelle als „paraphrase“ titulierten Modelle wurden mittels eines ähnlichen Ansatzes trainiert und sollen in Theorie bessere Ergebnisse liefern. Sowohl die veröffentlichte Tabelle als auch interne Tests haben dies bisher nicht bestätigt.
Die vorgestellte Herangehensweise verstärkt ein weiteres Problem von STS-Modellen: Die Checklisten-Einträge sind sehr kurz, wohingegen die Trainingsbeispiele vollständige Sätze umfassen. Gleichermaßen würde dieses Problem auch bestehen, wenn die Checklisten-Einträge sehr lang wären. Das Trainingsspektrum ist nicht breit genug gefasst, um diese Asymmetrie adäquat abzudecken.
Zu schlechter … guter Letzt stellt sich bei der Bewertung von semantischer Nähe auch die Frage, was genau im Fokus zweier Aussagen bzw. Sätze steht: Angenommen laut der Checkliste soll erkannt werden, ob ein Fenster geöffnet/geschlossen wird. In der Checkliste wird dazu das Label „Fenster öffnen/schließen“ und der Beispielsatz „Das Fenster in der Küche öffnen“ angelegt. Natürlich gibt es in der Liste noch weitere Einträge, beispielsweise „Badezimmer reinigen“ mit dem Satz „Das Badezimmer wurde gereinigt“. Gilt es nun den Satz „Ich habe das Fenster im Bad geöffnet“ korrekt einzuordnen, so scheint klar, dass es sich hierbei um das Label „Fenster öffnen/schließen“ handelt. Nach vielen prototypischen Aufbauten mussten wir jedoch feststellen: STS-Modelle „denken anders“ bzw. folgen sehr groben Konzepten. Konkret könnte dem Modell die Verbindung zwischen Bad und Badezimmer wichtiger vorkommen als der Prozess des Fenster öffnens. Diese Problematik variiert von Modell zu Modell und wird für manche Themenbereiche gut aufgelöst und für andere überhaupt nicht.
Diese Einschränkungen lassen sich durch eine enge Zusammenarbeit zwischen Pflegeeinrichtungen bzw. dem Gesundheitswesen und Software-Anbietern ausräumen. Es gilt realistische und spezifische Äußerungen anhand echter Szenarien in die Trainingsdaten aufzunehmen. STS-Modelle lassen sich dennoch prinzipiell in verschiedenen Szenarien einsetzen und bieten eine solide Basis für semantische Näheberechnung. Inwiefern Augmentation, Cross-Encoder und die Klassifizierung nach der SetFit-Methode zu einer weiteren Verbesserung der Robustheit solcher Modelle führen schauen wir uns in einem weiteren Blogbeitrag an.
Dieses Projekt ist eine Kollaboration zwischen der Technischen Hochschule Wildau und sense.ai.tion GmbH. Sie können uns wie folgt kontaktieren:
- Philipp Müller (M.Eng.); Autor
- Prof. Dr. Janett Mohnke; TH Wildau
- Dr. Matthias Boldt, Jörg Oehmichen; sense.AI.tion GmbH
This work was funded by the European Regional Development Fund (EFRE) and the State of Brandenburg. Project/Vorhaben: “ProFIT: Natürlichsprachliche Dialogassistenten in der Pflege”.













